IDENT_CURRENT(), SCOPE_IDENTITY(), 그리고 @@IDENTITY는 모두 SQL Server에서 IDENTITY 값을 반환하는 데 사용됩니다. 하지만 이들 간에는 몇 가지 차이점이 있습니다. 반환된 값이 현재 세션과 범위에 따라 다를 수 있으므로, 사용할 때는 주의해야 합니다.
IDENT_CURRENT()
IDENT_CURRENT() 함수는 임의 세션 및 범위에 있는 특정 테이블에 생성된 IDENTITY값을 반환합니다. 현재 세션이 아닌 다른 세션에서 해당 테이블에 마지막으로 데이터가 INSERT된 경우 그 값을 가져오므로 주의해야 합니다.
또한 지정한 테이블에 데이터가 하나도 없는 경우에 0이 아닌 1이 리턴되는 점도 유의할 필요가 있습니다.
예를 들어, 아래의 쿼리는 "Orders" 테이블에서 마지막으로 생성된 IDENTITY 값을 반환합니다.
SELECT IDENT_CURRENT('Orders');
SCOPE_IDENTITY()
SCOPE_IDENTITY() 함수는 현재 세션 및 범위 내에서 마지막으로 생성된 IDENTITY 값을 반환합니다. 이 함수는 현재 실행 중인 스크립트 또는 저장 프로시저에서 마지막으로 생성된 IDENTITY 값을 반환합니다. 다른 세션이나 트리거에서 생성된 IDENTITY 값은 반환하지 않습니다.
예를 들어, 아래의 쿼리는 "Orders" 테이블에 새로운 행을 삽입하고, 해당 행의 IDENTITY 값을 반환합니다.
INSERT INTO Orders (CustomerID, OrderDate)
VALUES ('ALFKI', '2023-01-01');
SELECT SCOPE_IDENTITY();
@@IDENTITY
@@IDENTITY 함수는 현재 세션에서 마지막으로 생성된 IDENTITY 값을 반환합니다. 만약 테이블에 트리거가 있고, 트리거에서 다른 테이블에 삽입된 행이 IDENTITY 값이 있는 경우 이를 반환 하게 되므로 사용에 주의 해야 합니다.
Identity Column을 사용하여 데이터를 입력할 때는 해당 컬럼의 값을 직접 입력할 필요가 없습니다.
INSERT INTO [테이블명]([Name], [Email])
VALUES ('John Doe', 'johndoe@example.com')
주의점
Identity Column은 테이블 내의 모든 레코드에서 고유한 값을 생성해야 합니다.
기존 레코드의 값을 수정할 경우, 고유한 값을 유지할 수 없으므로 주의해야 합니다.
SET IDENTITY_INSERT를 사용할 때에도 고유한 값을 유지하는 것을 확인해야 합니다.
SET IDENTITY_INSERT
Identity Column은 직접 값을 입력하는 것을 허용하지 않습니다. 하지만, 데이터를 마이그레션 한다든지 꼭 필요한 값으로 등록해야 하는 경우 SET IDENTITY_INSERT라는 기능을 사용하여 값을 직접 입력할 수 있는 것을 허용할 수 있습니다.
사용법
SET IDENTITY_INSERT 테이블명 ON/OFF
예시
SET IDENTITY_INSERT [dbo].[test_table] ON
GO
INSERT INTO [dbo].[test_table] ([ID], [Name], [Age])
VALUES (1, 'John Doe', 25)
GO
SET IDENTITY_INSERT [dbo].[test_table] OFF
GO
주의사항
Identity Column의 값이 기존의 레코드와 중복되면 오류가 발생할 수 있으므로 주의해야 합니다.
VALUES의 괄호 안에 올 수 있는 값은 상수, 변수 또는 식입니다(단, 식은 EXECUTE 문을 포함할 수 없습니다). 따라서 다음과 같이 사용자 정의 함수를 사용할 수도 있습니다.
INSERT INTO MyTable
VALUES (1, dbo.MyFunc(10, 20)),
(2, dbo.MyFunc(30, 40))
식이 가능하기 때문 다른 SELECT문이 포함될 수도 있습니다.
INSERT INTO dbo.MyProducts (Name, ListPrice)
VALUES ('Helmet', 25.50),
('Wheel', 30.00),
((SELECT Name FROM Production.Product WHERE ProductID = 720),
(SELECT ListPrice FROM Production.Product WHERE ProductID = 720));
SELECT .. FROM (VALUES)
INSERT뿐 아니라 SELECT의 FROM절에서도 VALUES를 사용할 수 있는데 일종의 가상 파생 테이블과 같다고 볼 수 있겠습니다.
SELECT a, b FROM (VALUES (1, 2), (3, 4), (5, 6), (7, 8), (9, 10) ) AS MyTable(a, b);
실행결과
앞서 INSERT .. VALUES에서 설명드린 것처럼 하나의 행을 하나의괄호로 묶고 쉼표로 구분하면 됩니다.
CROSS APPLY (VALUES)
CROSS APPLY 의 VALUES에서 공급받은 행의 값을 이용하여 다양하게 활용할 수 있습니다.
CREATE TABLE #temp
(
col1 int
, col2 int
, col3 int
, col4 int
, col5 int
)
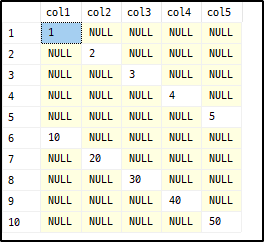
INSERT #temp VALUES(1,2,3,4,5), (10,20,30,40,50)
SELECT
CASE WHEN a.col1 = b.col THEN b.col END AS col1,
CASE WHEN a.col2 = b.col THEN b.col END AS col2,
CASE WHEN a.col3 = b.col THEN b.col END AS col3,
CASE WHEN a.col4 = b.col THEN b.col END AS col4,
CASE WHEN a.col5 = b.col THEN b.col END AS col5
FROM #temp a
CROSS APPLY (VALUES (a.col1),(a.col2),(a.col3),(a.col4),(a.col5)) b (col)
실행결과
CREATE TABLE #temp
(
col1 int
, col2 int
, col3 int
, col4 int
, col5 int
)
INSERT #temp VALUES(1,2,3,4,5), (10,20,30,40,50)
SELECT
a.*, b.total
FROM
#temp a
CROSS APPLY
(
SELECT SUM(x) total
FROM (VALUES (a.col1), (a.col2), (a.col3), (a.col4), (a.col5)) MyTable (x)
) b
실행결과
MERGE .. USING (VALUES)
MERGE문의 USING에 VALUES를 통해서 파생 원본 테이블로 사용할 수 있습니다.
MERGE INTO Sales.SalesReason AS Target
USING (VALUES ('Recommendation','Other'), ('Review', 'Marketing'), ('Internet', 'Promotion'))
AS Source (NewName, NewReasonType)
ON Target.Name = Source.NewName
WHEN MATCHED THEN
UPDATE SET ReasonType = Source.NewReasonType
WHEN NOT MATCHED BY TARGET THEN
INSERT (Name, ReasonType) VALUES (NewName, NewReasonType)
OUTPUT $action INTO @SummaryOfChanges;
(응용) 열 데이터에 대하여 집계 함수 사용
다음과 같이 열 데이터를 행으로 전환하는데 VALUES를 이용하여 한 행의 여러 칼럼 값들에 대하여 집계 함수를 사용할 수 있습니다.
CREATE TABLE #temp
(
col1 int
, col2 int
, col3 int
, col4 int
, col5 int
)
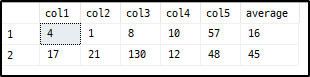
INSERT #temp VALUES(4,1,8,10,57), (17,21,130,12,48)
SELECT
col1, col2, col3, col4, col5
, ( SELECT AVG(a)
FROM (VALUES (col1), (col2), (col3), (col4), (col5)) x(a)
) average
FROM #temp